Как работает поисковик Яндекс — схемы и описания алгоритмов работы
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Интернет — просто охренеть какая огромная штука. И в нем есть все. Общение с друзьями? Вот, пожалуйста — Facebook. Фотоальбом — в Instagram. Купить дачу? У меня уже есть «Веселый фермер». А энциклопедией давно пользовались? Зачем, ведь есть поисковики, которые знают все. И сегодня мне бы хотелось отдать должное этим чудо-сервисам. А точнее рассказать вам о том, как работает Яндекс поиск.
Помните Гермиону из саги о Гарри Поттере? Как вы думаете: почему она была такой сверхэрудированной всезнайкой? Правильно, потому что постоянно ходила где-то читала про всякие зелья, изучала разные заклинания, допытывалась до учителей по всем непонятным моментам. В общем, делала все, чтобы расширить свою базу знаний. Точно так же работает Яндекс поисковик. Еще до того, как вы задали ему вопрос, он уже кое-что узнал про вашу тему и сохранил себе в копилочку.
Как формируется поисковая база Яндекса
Пауки всемирной паутины
Поисковик Яндекс знает несколько триллионов урлов. И каждый день он изучает по паре миллиардов из них. Делают это специальные роботы-пауки, краулеры. Они заходят на страницу, анализируют содержимое, делают копию и отправляют на сервер. А затем уходят по ссылкам на другие страницы. Так происходит знакомство поисковика с сайтом. Далее следует этап индексикации.
Если произвести нехитрые математические расчеты, то можно выявить, что пауки Яндекса обойдут все известные страницы приблизительно за 2 года. Но это будет неверно, так как количество урлов постоянно увеличивается
=> работа по созданию поисковой базы бесконечна.
Индексикация
Определение индекса сайта — это процесс добавления всей важной информации о странице в базу поисковика. То есть определяется язык, формируются данные об отдельных словах и вытаскиваются все ссылки исходящие на другие страницы. Кроме того у Yandex есть специальный инструмент, который называется логи Яндекса. Он изучает, как пользователь ведет себя в выдаче: на что кликает, а на что не кликает. Опираясь на все полученные параметры и задается поисковый индекс сайта.
Логи Яндекса широко применяются не только при индексикации, но и при ранжировании.
Составление поисковой базы
Поисковые индексы, полученные в ходе предыдущего этапа, отправляются в поисковую базу. У Яндекс поиска она функционирует на программной платформе мапредьюс YT. Здесь данные превращаются файлы и «остаются жить».
Суммарный объем данных YT приблизительно 50 петабайт = 51 200ТБ.
У поисковой базы данных есть еженедельное обновление — апдейт. Это тот момент, когда поисковый робот Яндекса, накачав определенное количество файлов и рассчитав для них все необходимые характеристики, принимает решение, что можно добавить эту информацию в поиск.
Согласно статистическим данным Игоря Ашманова — специалиста по поисковым системам в интернете, полнота поисковой базы у Яндекса (красные на графике) в несколько раз выше, чем у их ближайшего конкурента Google (черные).
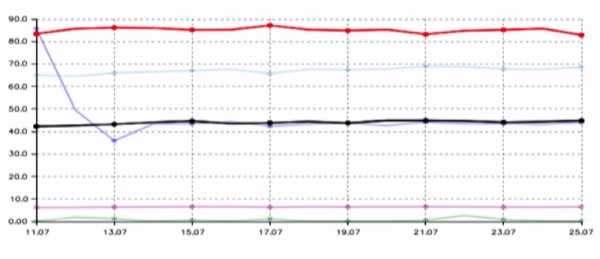
Пока индекс — времязатратный и протекает комплексно сразу для большого количества данных. Поэтому у Яндекса есть специальный быстрый контур, который может добавлять и доносить до пользователя отдельные, срочные файлы. Ну, например, новости в реальном времени.
Как работает сам Яндекс поиск
Любой запрос в поисковой системе Яндекс проходит по следующей схеме.
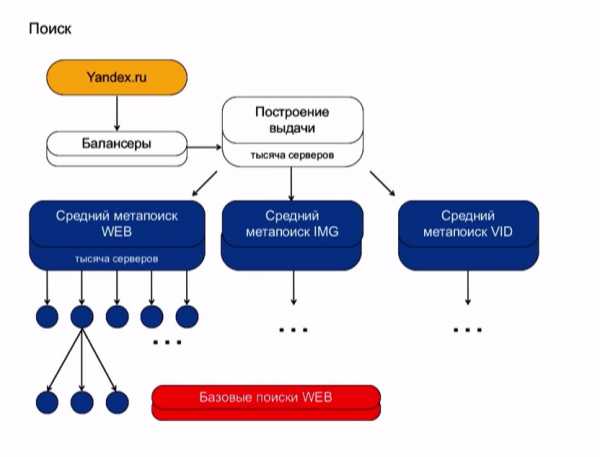
Балансеры — это машины, которые агрегируют выдачу.
Построение выдачи формируется из результатов трех средних метапоисков. Поясню, что это значит. В выдаче вы видите результаты запроса по страницам, картинкам и видео. Происходит это потому, что ваш запрос проходит по трем разным индексам. И по ним он спускается в самую-самую глубь поисковой базы, разделенную на несколько тысяч кусков. Этот процесс обозначается, как поисковая кластеризация.
Работа поискового кластера состоит из функционирования более миллиона экземпляров различных программ. Они выполняют всяческого рода задачи, у них разные системные требования и всем им нужно где-то «жить». Поэтому поисковая кластеризация занимает еще и огроменное количество компьютерного железного хостинга.
Для хранения и передачи всех программ и данных к ним Яндекс использует внутренний торрент-трекер. Число раздач на нем больше, чем на крупнейшем в мире пиратском трекере The Pirate Bay.
Вернемся к результатам выдачи.
В поисковую выдачу попадают наиболее релевантные, соответствующие поисковому запросу документы. Дальше происходит ранжирование — упорядочивание результатов поиска. Проходит оно с помощью специальной формулы. Чтобы порядок результатов каждый раз был качественным, актуальным и максимально релевантным разработчики Яндекса придумали одну очень крутую штуку.
Матрикснет — метод машинного обучения, с помощью которого строится формула ранжирования Яндекс. Он постоянно модернизирует эту схему: выстраивает комбинации, добавляет и убирает факторы, выставляет коэффициенты. Другая важная характеристика этого метода — возможность индивидуальной настройки формулы ранжирования для узкопрофильных категорий запросов. То есть для отдельных запросов, например, про кино или компьютерные игры, можно улучшить качество поиска. При этом ранжирование по остальным классам запросов не ухудшится.
Первая формула ранжирования Яндекса составляла примерно 10 байт. На сегодняшний момент — около 100 мегабайт.
Задача поисковика не просто находить иголки в сеновалах, но и определять самые острые из них. И самое удивительное то, как работает Яндекс поиск. Результат выдается за доли секунд. Десять первых наиболее релевантных запросов — как правило, это все, что нужно пользователю. Если в этих запросах мы не находим то, что искали, то мы пробуем или другой запрос, или меняем поисковик. Но рано или поздно: «Найдется все!»
Скриншоты взяты из лекции Петра Попова.
icon by Arthur Shlain
Работа в Яндексе
Посмотрите ролик о том, как устроен процесс интервью в Яндексе.
1
Как на него попасть
Почти у каждой вакансии Яндекса есть тестовое задание — с него-то всё и начинается. Ответьте на вопросы на странице вакансии и отправляйте заявку. Если вы успешно справились с тестом и заинтересовали службу найма, то получите приглашение на встречу — обычно в течение недели.
Резюме
Подойдёт в любой форме, а для дизайнеров и разработчиков его заменит портфолио или ссылка на репозиторий. Хорошо сопроводить резюме вольным рассказом о том, почему вас стоит взять на работу. Будьте готовы вкратце пересказать ключевые факты на собеседовании — умение представить себя интересует не меньше биографии.
Сколько будет встреч
Чаще всего проводятся четыре собеседования. В некоторых случаях в зависимости от профессии кандидата решение о найме может быть принято по итогам двух встреч. На особо ответственные должности количество интервью может быть увеличено до пяти-шести.
2
Как оно проходит
Обычно встреча длится час или два. Вам предложат чай-кофе, воду и печеньки. Собеседование с претендентами на вакансию разработчика состоит из серии коротких встреч с разными экспертами. Рекрутер обязательно расскажет вам все подробности.Подробности для технических вакансий
Подробности для дизайнеров
Кто будет на собеседовании
Сотрудник отдела найма и ваш потенциальный руководитель. Если вы подходите на несколько ролей или претендуете на важную должность, к встрече могут присоединиться и другие эксперты.
Чего ожидать
Некоторые вопросы или задачки могут не касаться вакансии напрямую — так проверяется способность рассуждать в неизвестной ситуации. Также будьте готовы начертить схему маркером на стене или написать код на бумаге, без компьютера.
3
Что будет после
Между встречами и особенно после финального собеседования иногда наступает длинная пауза. Пожалуйста, наберитесь терпения. Если рекрутер не ответил на звонок или письмо — это не значит, что вы не справились. В это время служба найма может общаться с другими кандидатами, а итоговое тестовое задание часто проверяют много людей.
В случае успеха
Рекрутер сразу свяжется с вами и озвучит предложение Яндекса. В первый день в офисе вас встретят, помогут оформить документы в отделе кадров, получить оборудование и освоиться на рабочем месте.
Если отказали
Поищите другие вакансии — если вы не прошли тестовое задание или собеседование, ничто не мешает попробовать себя в другой роли. Или повторить заявку через какое-то время, когда наберётесь знаний и опыта.
yandex.ru
Подробная инструкция, как работать с Яндекс Вебмастером
Яндекс.Вебмастер – отличный, а главное бесплатный сервис Яндекса для мониторинга работы сайта, его настроек и своевременного выявления технических проблем. Присутствие сайта в Яндекс.Вебмастере – очень и очень желательно. Давайте разберемся, что же в нем такого полезного и как с этим работать.
Какие задачи решает Яндекс.Вебмастер?
С помощью Яндекс.Вебмастера вы можете:
Но, чтобы воспользоваться всеми перечисленными возможностями, прежде всего необходимо добавить ваш сайт в Яндекс.Вебмастер.
Как добавить сайт в Яндекс.Вебмастер?
Следуйте инструкции:
- Авторизуйтесь под своим аккаунтом в Яндекс.
- В интерфейсе Вебмастера по адресу https://webmaster.yandex.ru/sites/add/ укажите адрес вашего сайта. Учитывайте префикс WWW, протоколы https и http. Нажмите кнопку «Добавить».
- Сейчас нам нужно подтвердить права на сайт. Добавьте HTML файл со специальным именем в корень сайта, либо разместите мета-тег с кодом на главной странице сайта.
Добавление сайта в Вебмастер помогает поисковой системе быстрее узнать о его существовании и начать индексирование.
Добавили сайт в Вебмастер, что дальше, как с ним работать? Двигаемся по пунктам.
Главный экран. Сводка
Отображает основную и самую важную информацию о вашем сайте.
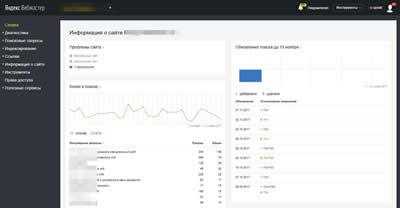
- Клики в поиске и популярные запросы.
- Проблемы, найденные на сайте.
- Последние внешние ссылки на ваш сайт.
- 10 последних изменений в индексации сайта.
- История тИЦ.
Ниже каждый из этих пунктов мы разберем подробно.
Раздел Диагностика
Содержит информацию об ошибках, найденных на вашем ресурсе. Сайт проверяется каждый день. Все ошибки делятся на 4 вида: рекомендации, возможные проблемы, критичные, фатальные.
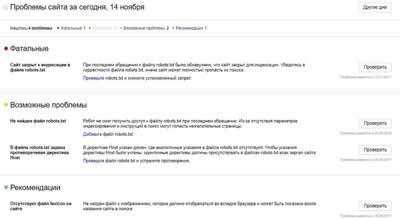
Большинство ошибок носит рекомендательный характер и не влияет на индексацию и ранжирование сайта, кроме разделов «Критичные» и «Фатальные». На эти разделы следует обращать особое внимание. Тут отображаются санкции, доступность сайта для поискового робота, время ответа сервера и т.д. Все ошибки можно найти здесь.
После исправления ошибки обязательно сообщите об этом Яндексу. Просто нажмите кнопку «Проверить».
Раздел Поисковые запросы
Раздел содержит информацию о поисковых фразах, по которым сайт показывается на первых 50 позициях результатов поиска Яндекса. Более подробно о данном разделе мы уже рассказывали в блоге.
Если коротко, то в этом разделе вы можете посмотреть:
История запросов
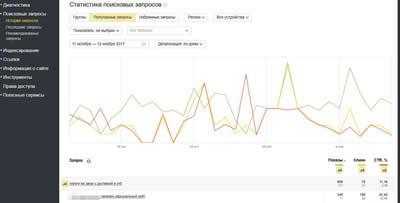
Показывается полная статистика всех поисковых запросов за выбранный период. Доступна вся статистика начиная с 1 октября 2015 года.
Важно: Статистика Яндекс.Вебмастера, Wordstat и Яндекс.Метрики может различаться. Это связано с некоторыми техническими аспектами, например, сервисы могут по-разному учитывать время перехода, Яндекс.Вебмастер учитывает только часть данных из поисковой выдачи. Подробнее о различиях рекомендую прочитать в Яндекс Справке.
Работая в этом отчете, вы можете разделить запросы по группам и времени, можете выбрать тип устройства. Статистика по типу позволяет разделить переходы с мобильных устройств и с десктопа.
Раздел помогает отследить динамику запросов, рост позиций, CTR сниппета в поисковой выдаче.
Проанализировать количество кликов с позиций и CTR сниппета сайта:
Отслеживая эту информацию, мы можем корректировать сниппеты сайта в поисковой выдаче. Как косвенно влиять на сниппет сайта в выдаче Яндекс, мы рассказывали в этой статье.
Вкладка Тренды отражает динамику трафика вашего сайта в сравнении с конкурентами.
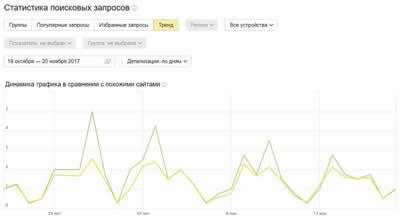
На графике отображается динамика относительного количества переходов на ваш сайт (зеленый график) и сайтов конкурентов (желтый график). Данные отображаются в усредненном варианте, что позволяет увидеть общую картину по динамике переходов из поисковой выдачи.
График помогает отследить, как влияют изменения на сайте на переходы из результатов поиска. К примеру, если вы заметили общее снижение трафика у вас и у похожих сайтов, скорее всего, причина тому сезонность.
Если только ваш график пошел вниз, а похожие сайты продолжают расти, что-то пошло не так и нужно искать причину.
Последние запросы
Запросы формируются автоматически на базе ТОП-50 результатов выдачи Яндекс с показом больше одного, т.е. в данном разделе можно увидеть, по каким ключевым запросам и на какой средней позиции ваш сайт был в выдаче, сколько раз пользователи кликнули и перешли на сайт. Данные запросы можно использовать для расширения семантического ядра сайта.
Также есть возможность загрузить собственные запросы и по ним отслеживать статистику показов и кликов.
Рекомендованные запросы
Яндекс может подсказывать, по каким еще запросам вас могут искать пользователи, что приводит дополнительный трафик. Кроме запросов, раздел отображает целевую страницу по данному ключевому слову.
Рекомендованные запросы можно использовать при ведении рекламной кампании в качестве условия таргетирования, использовать для расширения СЯ сайта и в качестве идей для нового контента на сайте.
Раздел Индексирование
Самый крупный раздел в Вебмастере. Зимой 2016 года его довольно сильно обновили. Об основных изменениях можно прочитать здесь.
Робот Яндекса регулярно обходит страницы сайтов и добавляет их в свою базу. Некоторые страницы могут быть недоступны для робота, закрыты от индексации, либо удалены с сайта. Данный раздел позволяет в подробностях узнать, какая страница находится в индексе, какая удалена и почему. Пробежимся по разделам.
Статистика обхода
Раздел позволяет узнать, какие страницы сайта обошел робот Яндекса. Если сайт был недоступен какое-то время, список всех недоступных страниц будет виден для анализа. Если страница недоступна продолжительное время, позиции сайта будут понижены.
Страницы в поиске
Отображает страницы сайта, которые участвуют в поиске Яндекса. Можно отследить, какая конкретно страница сейчас участвует в поисковой выдаче, какие были исключены.
Страница может быть исключена по нескольким причинам:
- дубль;
- недостаточно качественная страница;
- редирект;
- страница закрыта от индексации;
- страница удалена.
Как бороться с дублями, подробно мы рассказывали в этой статье. В двух словах, используйте тег canonical, закрывайте от индексации все фильтры, поиск и прочие служебные страницы. Недостаточно качественные страницы рассчитываются по особому алгоритму Яндекс. Как правило, это страницы с парой предложений текстов, без полезного контента для пользователей.
Структура сайта
Отображает разделы сайта, содержащие более 10 страниц. Показывает общее количество загруженных страниц и страниц, находящихся в поиске.
- Загруженные страницы – это страницы, которые смог найти робот и добавить в свою базу.
- Страницы в поиске – страницы, представленные в SERP Яндекс. Если страница некачественная, дублирует контент, либо недоступна, она не будет отображаться в результатах выдачи.
Помогает обнаружить служебные разделы сайта и закрыть их от индексации в файле robots.txt.
Проверить статус URL
Инструмент для отслеживания индексирования определенных страниц поисковым роботом. Можно проверить, знает ли Яндекс о конкретной странице. Просто скопируйте url адрес в поисковую строку. Обновление может занимать до нескольких часов.
Важные страницы
Яндекс предоставляет возможность отслеживать индексацию самых важных страниц сайта. Можно узнать о появлении новой страницы, участвует она или нет в поисковой выдаче и т.д.
Список важных и популярных страниц можно увидеть чуть ниже, в разделе «Рекомендованные страницы».
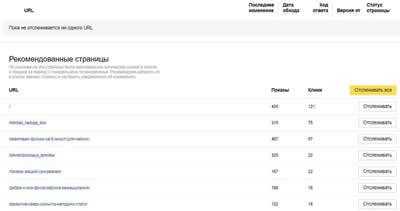
Чтобы добавить страницы, просто скопируйте их в соответствующее поле и нажмите «отслеживать».
Переобход страниц
Помогает сообщить поисковому боту о новых и обновленных страницах. Функция полезна при обновлении текста на сайте, изменении изображений и т.д. В своей работе мы часто используем ее, если нужно вывести сайт из-под фильтров.
Файлы Sitemap
Чтобы ускорить индексацию, используется специальный xml-файл. Документ содержит в себе полную структуру сайта и адреса всех страниц. Как создать такой файл, читайте в этой статье.
Переезд сайта
Позволяет сообщить Яндексу о смене адреса сайта. Также используется при переносе сайта на https, смене главного зеркала сайта. Инструмент помогает снизить риски при переезде на новый домен, сохранить позиции и количество страниц в индексе *.
* К сожалению, даже если вы воспользуетесь этой функцией Яндекс.Вебмастера, Яндекс не гарантирует сохранение позиций и всех страниц в индексе.
Раздел Ссылки
Содержит информацию о внутренних и внешних ссылках на сайт.
Внутренние ссылки
Здесь отображаются все найденные битые ссылки, расположенные на сайте и ведущие на другую страницу вашего же сайта. Большое количество битых ссылок негативно влияет на пользовательский опыт, мешает навигации, ухудшает поведенческие факторы.
При обнаружении таких ссылок их важно исправить. Обновление происходит после переиндексации сайта роботом. Также битые ссылки можно найти с помощью сторонних сервисов, к примеру brokenlinkcheck.com.
Внешние ссылки
Раздел отображает внешние ссылки на ваш сайт, обнаруженные роботами Яндекс. Как правило, доступны далеко не все внешние ссылки.
Ссылки можно группировать по сайтам, либо показывать только неработающие внешние ссылки.
Удобный инструмент для анализа ссылочного профиля сайта. Рекомендуем использовать вместе со сторонними сервисами, вроде SE Ranking, MegaIndex и т.д. Если не сможете разобраться, будем рады помочь. У нас данная услуга входит в SEO-аудит сайта.
Раздел Информация о сайте
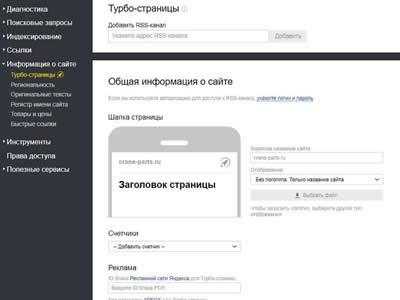
Турбо-страницы
Раздел для создания специальных быстрых страниц для мобильных устройств. Содержимое страницы хранится на серверах Яндекса, и он загружает страницу без обращения к вашему сайту.
Технология используется для показа сайтов на мобильных устройствах:
- в результатах поиска, если ваш сайт уже участвует в поиске;
- в сюжетах Яндекс.Новостей, если вы партнер Яндекс.Новостей;
- в ленте Яндекс.Дзена, если вы размещаетесь в Яндекс.Дзене.
Турбо-страницы отмечены значком ракеты .
На мобильных устройствах на плохом 3G интернете такие страницы загружаются в 15 раз быстрее.
В данный момент все страницы создаются по единому шаблону. Логотип сайта в верхней части, текст с изображениями и рекламный блок.
Как включить турбо-страницы:
- Создайте специальный rss-канал.
- Передайте информацию в Вебмастер Яндекс.
- Включите показ Турбо-страниц.
Региональность
Содержит информацию о регионе, определенном в данный момент для вашего сайта.
Если ресурс ориентирован на геозависимые запросы, то обязательно проследите за тем, чтобы региональность сайта была определена корректно, так как она может учитываться при определении релевантности сайта запросам из того или иного региона.
Если у вас сайт общей тематики, рассчитанный на пользователей из всех регионов, то регион можно не присваивать. Сайтам общей тематики, вроде порталов, блогов и т.п. может быть присвоен статус «Не имеет региональной принадлежности».
Сайту не может быть присвоен статус «Не имеет региональной принадлежности», если он посвящен товарам конкретной организации, у которой имеется физический или юридический адрес.
Оригинальные тексты
Все тексты, размещенные на сайте, должны быть написаны в единственном экземпляре и нигде кроме этого сайта не повторяться. Уникальные тексты способствуют продвижению сайта и повышают доверие пользователей к вашему ресурсу.
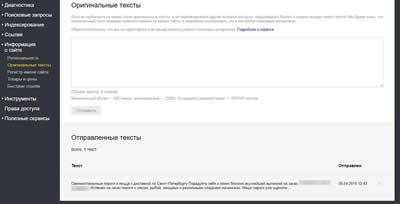
В данном разделе можно закрепить права на текст перед его размещением. Еще раз, важно закреплять права до размещения текста на страницах сайта. Если текст уже размещен и скопирован на другие ресурсы, закреплять авторство бесполезно.
Еще много полезных советов о том, как защитить свой оригинальный контент, читайте в нашей статье.
Регистр имени сайта
В данном разделе можно изменить регистр имени сайта. Это никак не влияет на ранжирование, но позволяет сделать его удобным и более информативным для пользователей.
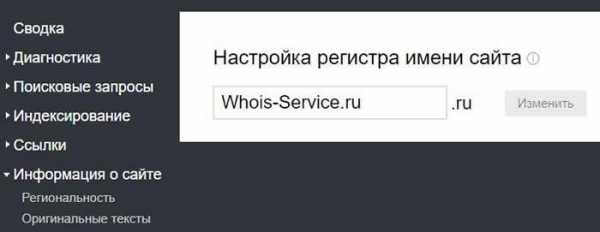
К примеру, домен http://www.whois-service.ru/ может отображаться в поисковой выдаче как Whois-Service.ru
Товары и цены
Если вы владелец интернет-магазина или представитель офлайн-магазина, в данном разделе можно разместить информацию о магазине и предоставить данные о предлагаемых товарах. Данные будут использоваться для улучшения представления вашего сайта в результатах поиска. В сниппет сайта можно добавить цену и условия доставки в конкретный регион.
Примеры сниппетов с дополнительной информацией и без:
Быстрые ссылки
Быстрые ссылки – это короткий путь из результатов выдачи к важной информации на вашем сайте. Робот Яндекса сам формирует быстрые ссылки на основе данных посещаемости и полезности страниц конкретного сайта.
В данном разделе мы можем управлять уже сформированным быстрыми ссылками: полностью отключить отображение ссылок в поисковой выдаче, показывать или нет конкретную ссылку, выбрать имя ссылки из предложенных вариантов.
Раздел Инструменты
Набор полезных бесплатных инструментов для анализа вашего сайта.
Анализ robots.txt
Можно проверить, правильно ли составлен файл robots.txt. Тут отображаются строки, используемые роботами Яндекса при индексировании сайта. Также можно проверить на доступность конкретную страницу или список страниц, раздел «Разрешены ли URL»
Анализ файлов Sitemap.xml
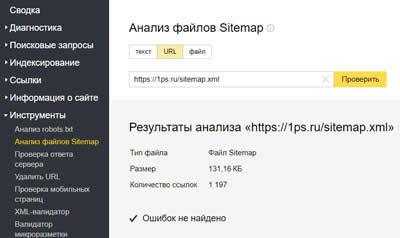
Проверяем файл карты сайта на ошибки, перед тем как отправить ее в Яндекс.Вебмастер.
Проверка ответа сервера
Инструмент для проверки доступности сайта поисковым роботам Яндекс.
Можно менять роботов, посмотреть время ответа сервера, узнать Содержимое страницы – то, как робот видит ваш сайт своими «глазами».
Страницы сайта должны быть всегда доступны и отдавать 200-й ответ. Несуществующие страницы отдают 404-й ответ и недоступны поисковым роботам.
Удалить URL
Специальный инструмент для удаления страницы из поисковой выдачи. Можно удалить несуществующую страницу, к примеру, товар, который больше никогда не будет продаваться на вашем сайте.
Проверка мобильных страниц
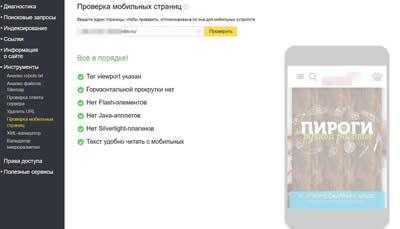
Инструмент для проверки оптимизации конкретной страницы для мобильных устройств. Сегодня все поисковые системы отдают предпочтения сайтам, оптимизированным под мобильные устройства. Важно, чтобы ваш сайт был правильно оптимизирован и корректно отображался на смартфонах, планшетах и т.д.
XML-валидатор
Инструмент для проверки XML-файлов для партнерских программ Яндекса. Помогает выявить ошибки, проверить сайт под разные схемы валидации.
Валидатор микроразметки
Проверяем наличие и корректное размещение микроразметки на своем сайте. Используя семантическую разметку, вы можете улучшить представление сниппета вашего сайта в результатах поиска. Расширить описание, показать телефон, адрес, режим работы компании. Помочь роботам лучше понимать, о чем сайт. Соответственно улучшить ранжирование.
Так выглядит сайт с семантической разметкой отзывов:
Раздел Права доступа
Раздел для делегирования прав другим пользователям Яндекс. Просто введите e-mail пользователя и нажмите «Делегирование прав».
Инструкция, как работать с Яндекс Вебмастером готова, если есть что добавить, пишите в комментарии, отвечу на все вопросы 🙂 Если возникнут сложности с установкой, обращайтесь к нам, настроим Вебмастер Яндекс и Google в рамках услуги – Поисковое продвижение сайтов.
Используя инструменты Вебмастера, вы получаете отличный, бесплатный сервис для анализа и развития своего сайта. Must have для всех вебмастеров и владельцев сайтов.
1ps.ru
Алгоритмы и технологии Яндекса. Как работает поиск?
В прошлой статье мы рассмотрели наиболее интересные технологии Яндекса, применяемые для обеспечения качественного поиска в интернете. Теперь разберем более подробно, как устроена поисковая машина Яндекса. Что же происходит после того, как пользователь вводит запрос в строку поиска?
MatrixNet
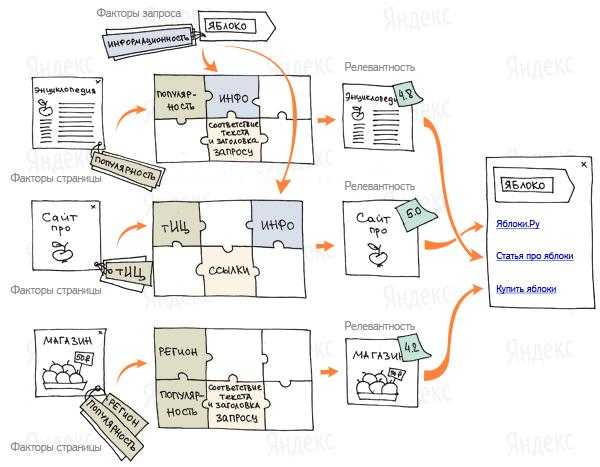
Технология поиска Яндекс устроена сложно. Поисковая выдача формируется на основе формулы ранжирования, построенной на нескольких сотнях факторов, каждый из которых может включаться с индивидуальным коэффициентом, а также в различных комбинациях с прочими факторами.
Формула ранжирования — это функция, построенная на множестве факторов, при помощи которых определяется релевантность сайта поисковому запросу и его очередность в выдаче
Для обеспечения качественного поиска факторы и коэффициенты в формуле ранжирования должны регулярно обновляться. Построением такой формулы в Яндексе занимается MatrixNet (Матрикснет) — метод машинного обучения, введенный Яндексом в 2009 году с целью сделать поиск более точным.
«Матрикснет» — метод машинного обучения, с помощью которого подбирается формула ранжирования Яндекса. Входными данными являются факторы и обучающие данные, подготовленные асессорами (экспертными сотрудниками Яндекса).
Основная его особенность заключается в том, что он устойчив к переобучению и позволяет построить сложную формулу ранжирования с десятками тысяч коэффициентов, которая учитывает множество различных факторов и их комбинаций без увеличения количества асессорских оценок и опасности найти несуществующие закономерности.
Архитектура поиска
Ежедневно пользователи посылают Яндексу десятки миллионов запросов. Для формирования ответа под какой-нибудь один запрос поисковой машине необходимо проверить миллионы документов, определить их релевантность и упорядочить при помощи формулы ранжирования так, чтобы наиболее подходящие страницы сайтов оказались вверху выдачи. Для ускорения этого процесса Яндекс использует заранее подготовленные данные — индекс.
Индекс — база поисковой системы, содержащая сведения о запросах и их позициях на страницах сайтов в сети. Индекс формируется поисковым роботом, который обходит сайты и собирает информацию с заданной периодичностью.
Размер индекса в поиске огромен, чтобы быстро обработать такой объем данных используются тысячи серверов, объединенные в кластеры.
После того, как пользователь вводит запрос в строку поиска, он анализируется компьютерной системой «Метапоиск» на предмет региональной привязки, класса запроса и т.д. Там же запрос проходит лингвистическую обработку. Далее «Метапоиск» проверяет кэш на наличие поискового ответа по данному запросу. По часто задаваемым запросам результаты поиска хранятся в памяти поисковика в течение какого-то времени, а не формируются каждый раз заново.
«Метапоиск» — это программа, которая принимает и разбирает поисковые запросы, передает их соответствующим «Базовым поискам», обеспечивает агрегацию и ранжирование найденных документов, а также производит кеширование части ответов, которые впоследствии возвращаются пользователям без обращения к «Базовому поиску».
Если же ответ не найден, «Метапоиск» передает запрос другой компьютерной системе – «Базовому поиску». Там же хранится поисковая база Яндекса (индекс). Так как это огромный объем данных, индекс разбивается на части, которые хранятся на разных серверах. Такой подход позволяет производить поиск одновременно по нескольким частям базы данных, что заметно ускоряет процесс. Каждый сервер имеет несколько копий, это дает возможность распределять нагрузку и не терять данные. При передаче запроса «Метапоиск» выбирает наименее загруженные сервера «Базового поиска».
«Базовый поиск» обеспечивает поиск по всей части индекса (базе поисковой системы), содержащей сведения о запросах и их позициях на страницах сайтов в сети.
Каждый сервер базового поиска отдает список документов, содержащих поисковый запрос, обратно в «Метапоиск», где они ранжируются по сформированной «Матрикснетом» формуле. Результаты такой работы мы видим на странице выдачи.
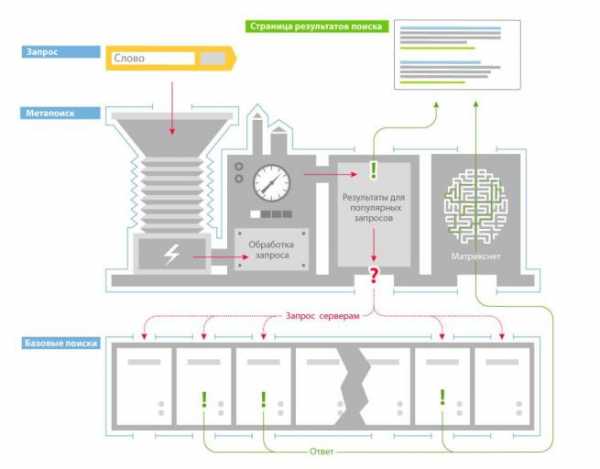
Использование индекса в качестве источника данных, многостадийный подход к формированию ответа и дублирование данных позволяют Яндексу обеспечивать поиск за доли секунды.
Оценка качества поиска
Помимо скорости поиска не менее важно и его качество. Для этого у Яндекса существует система оценки качества поиска, которая также помогает улучшить это качество.
Релевантность – свойство документа, определяющее степень его соответствия поисковому запросу. Вычисляется на основе формулы ранжирования.
Релевантность документа поисковому запросу вычисляется на основе формулы ранжирования – функции от множества факторов. Сейчас в Яндексе более 800 различных факторов, таких как возраст сайта, региональная привязка, взаимодействие пользователей с сайтом (поведенческий фактор), уникальность контента и т.д. В случае с персонализированным поиском релевантность документа зависит непосредственно от предпочтений пользователя, отправившего запрос.
Формула ранжирования постоянно обновляется, так как меняются потребности пользователей и индекс поисковика. Для ее обновления применяется методы машинного обучения. На основе экспертных данных выявляются зависимости между характеристиками документов и порядком их включения в выдачу, которые вносятся в формулу для ее корректировки.
Оценка качества поиска — удовлетворенность пользователей результатами поиска и порядком их следования.
Экспертными данными для машинного обучения являются оценки асессоров, которые также применяются для оценки качества поиска.
Асессоры — специалисты, оценивающие по ряду критериев релевантность представленного в выдаче документа поисковому запросу.
Асессоры оценивают поисковые результаты в выдаче по ряду критериев, которые позволяют определить, присутствует ли на сайте полный ответ на запрос, является ли сайт брендовым, не переспамлен ли текстовый контент и т.д. В основном асессоры работают с наиболее популярными поисковыми запросами (порядка 150 тыс.), при этом оцениваются первые 30 позиций выдачи. Это наиболее авторитетная оценка, так как ее проводит человек, а не машина, т.е. сайт получает оценку с точки зрения пользователя.
Актуализация и улучшение правил ранжирования в комплексе с оценкой качества поиска помогают Яндексу формировать выдачу, соответствующую ожиданиям пользователей.
www.iseo.ru
Поисковая система Яндекс ру — Поисковое продвижение и web аналитика простыми словами
 Добрый день, уважаемые читатели моего сео блога. Эта статья о том, как работает поисковая система Яндекс, какие она использует технологии и алгоритмы для ранжирования сайтов, что делает для подготовки ответа пользователям. Многие знают, что этот флагман русского поиска задает тон в Рунете, владеет самой большой базой данных в Евразии, оперирует контентом более чем миллиарда страниц, знает ответ на любой вопрос. По данным Liveinternet за август 2012 года, доля Яндекса в России составляет 60,5%. Месячная аудитория портала — 48,9 миллионов человек. Но самое главное, для нас, блоггеров в том, как поисковая система получает наши запросы, как их обрабатывает и какой результат получается на выходе. С одной стороны, зная и понимая эту информацию, нам проще пользоваться всеми ресурсами Яндекса, с другой стороны — легче продвигать наши блоги. Поэтому, предлагаю вместе со мной посмотреть самые важные технологии лучшей поисковой системы Рунета.
Добрый день, уважаемые читатели моего сео блога. Эта статья о том, как работает поисковая система Яндекс, какие она использует технологии и алгоритмы для ранжирования сайтов, что делает для подготовки ответа пользователям. Многие знают, что этот флагман русского поиска задает тон в Рунете, владеет самой большой базой данных в Евразии, оперирует контентом более чем миллиарда страниц, знает ответ на любой вопрос. По данным Liveinternet за август 2012 года, доля Яндекса в России составляет 60,5%. Месячная аудитория портала — 48,9 миллионов человек. Но самое главное, для нас, блоггеров в том, как поисковая система получает наши запросы, как их обрабатывает и какой результат получается на выходе. С одной стороны, зная и понимая эту информацию, нам проще пользоваться всеми ресурсами Яндекса, с другой стороны — легче продвигать наши блоги. Поэтому, предлагаю вместе со мной посмотреть самые важные технологии лучшей поисковой системы Рунета.
Когда пользователь Интернета впервые хочет обратиться за информацией к поисковой системе, у него может возникнуть один вопрос: «Как происходит поиск?» Но когда он ее получает, зачастую этот вопрос меняется на другой: «Почему так быстро?» И действительно, почему поиск какого-нибудь файла на компьютере занимает 20 секунд, а результат запроса со всей сети компьютеров по всему миру появляется через секунду? Самое интересное, что первых два вопроса (как происходит поиск и почему 1 секунда) могут быть в одном ответе — поисковая система заранее подготовилась к запросу пользователя.
Чтобы понять принцип работы Яндекса, как и другой поисковой системы, проведем аналогию с телефонным справочником. Чтобы найти любой номер телефона, необходимо знать фамилию абонента и любой поиск занимает в таком случае максимум минуту, потому что все страницы справочника — это сплошной алфавитный указатель. А вот представьте себе, если бы поиск шел по другому варианту, где номера телефонов были бы упорядочены по самим номерам. После таких поисков, которые уже затянутся на более продолжительное время, цифры перед глазами искавшего будут еще очень долго стоять. 🙂
Так и поисковая система раскладывает всю информацию из Интернета в удобном для нее виде. И самое главное, все эти данные заранее кладутся в ее справочник, до прихода посетителя со своими запросами. То есть, когда мы задаем Яндексу вопрос, он уже знает наш ответ. И выдает нам его через секунду. Но эта секунда включает в себя ряд важнейших процессов, которые мы сейчас подробно рассмотрим.
Индексирование Интернета
Яндекс ру собирает в сети Интернет всю информацию, до которой может дотянутся. С помощью специального оборудования, отсматривается весь контент, в том числе и изображения по визуальным параметрам. Занимается таким сбором поисковая машина, а сам процесс сбора и подготовки данных называется индексированием. В основу такой машины входит компьютерная система, которая по другому именуется поисковый робот. Он регулярно обходит проиндексированные сайты, проверяет их на наличие нового контента, а также сканирует Интернет в поисках удаленных страниц. Если он обнаруживает, что какая-то такая страница больше не существует или закрыта от индексирования, то удаляет ее из поиска.
Как поисковый робот находит новые сайты? Во-первых, благодаря ссылкам с других сайтов. Потому что если на новый веб-ресурс поставлена ссылка с уже проиндексированного сайта, то при следующем посещении второго, робот зайдет в гости и к первому. Во-вторых, в Вебмастере поисковика Яндекс есть чудесный сервис, в народе называемый «аддурилка» (от словосочетания на английском языке -addurl — добавить адрес). В нем можно внести адрес Вашего нового сайта, который через некоторое время посетит поисковый робот. В-третьих, с помощью специальной программы «Яндекс.Бар» отслеживается посещение пользователей, которые ею пользуются. Соответственно, если человек попал на новый веб-ресурс, в скором времени там появится и робот.
Все ли страницы попадают в поиск? Каждый день индексируются миллионы страниц. Среди них есть страницы различного качества, в которых может содержатся разная информация — от уникального контента до сплошного мусора. Причем, как говорит статистика, мусора в Интернете намного больше. Каждый документ поисковый робот анализирует с помощью специальных алгоритмов. Он определяет, есть ли у него какая-нибудь полезная информация, сможет ли он ответить на запрос пользователя. Если нет, то такие страницы не берут «в космонавты», если же да, то он включается в поиск.
После того, как робот посетил страницу и определил ее полезность, она появляется в хранилище поисковой машины. Здесь идет разбор любого документа до самых основ, как говорят мастера автоцентра — до винтиков. Страница очищается от html-разметки, чистый текст проходит полную инвентаризацию — подсчитывается местоположение каждого слова. В таком разобранном виде страница превращается в таблицу с цифрами и буквами, которую по другому называют индексом. Теперь, чтобы не случилось с веб-ресурсом, в котором содержится эта страница, ее последняя копия всегда есть в поиске. Даже если сайт уже не существует, слепки его документов еще некоторое время хранятся в Интернете.
Каждый индекс вместе с данными о типах документов, кодировке, языке вместе с копиями составляют поисковую базу. Она периодически обновляется, поэтому находится на специальных серверах, с помощью которых происходит обработка запросов пользователей поисковой системы.
Как часто происходит процесс индексации? В первую очередь это зависит от типов сайтов. Веб-ресурс первого типа очень часто меняет содержимое своих страниц. То есть, когда к этим страницам каждый раз приходит поисковый робот, они каждый раз содержат другой контент. По ним ничего в следующий раз уже не получится найти, поэтому такие сайты не включаются в индекс. Второй тип сайтов — хранилища данных, на страницах которых периодически добавляются ссылки на документы для скачивания. Контент такого сайта обычно не меняется, поэтому его робот посещает крайне редко. Другие сайты зависят от частоты обновления материала. Имеется в виду следующее — чем быстрее появляется новый контент на сайте, тем чаще приходит поисковый робот. И приоритет отдается в первую очередь наиболее важным веб-ресурсам (новостной сайт на порядок важнее, чем любой блог, к примеру).
Индексирование позволяет выполнить первую функцию поисковой системы — сбор информации на новых страницах в сети Интернет. Но у Яндекса есть и вторая функция — поиск ответа на запрос пользователя в уже подготовленной поисковой базе.
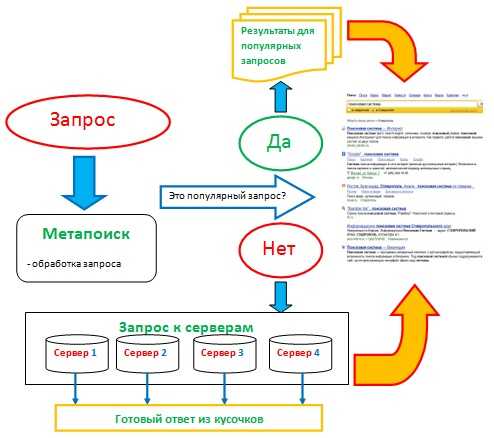
Яндекс готовит ответ
Процессом обработки запроса и выдачей релевантных ответов занимается компьютерная система «Метапоиск». Для своей работы сначала она собирает всю вводную информацию: из какого региона был осуществлен запрос, к какому классу относится, есть ли ошибки в запросе и т.д. После такой обработки метапоиск проверяет, есть ли в базе точно такие же запросы с такими же параметрами. Если ответ положительный, то система показывает пользователю заранее сохраненные результаты. Если же такого вопроса в базе не существует, метапоиск обращается поисковой базе, в которой содержатся данные индекса.
И вот здесь происходят удивительные вещи. Представьте себе, что существует один супермощный компьютер, который хранит в себе весь обработанный поисковыми роботами Интернет. Пользователь задает запрос и в ячейках памяти начинается поиск всех документов, причастных к запросу. Ответ найден и все довольны. Но возьмем другой случай, когда появляется очень много запросов, содержащих в своем теле одинаковые слова. Система должна каждый раз пройтись по одним и тем же ячейкам памяти, что может увеличить время на обработку данных в разы. Соответственно, увеличивается время, что может привести к потери пользователя — он обратится за помощью к другой поисковой системе.
Чтобы таких задержек не было, все копии в индексе сайтов распределены по разным компьютерам. После передачи запроса, метапоиск дает команду таким серверам искать свой кусочек с текстом. После чего, все данные от этих машин возвращаются в центральный компьютер, он объединяет все полученные результаты и выдает пользователю первую десятку самых лучших ответов. С такой технологией сразу убивается два зайца: в несколько раз уменьшается время поиска (ответ получается за доли секунды) и благодаря увеличению площадок дублируется информация (данные не теряются из-за внезапных поломок). Сами компьютеры с дублирующей информацией составляют дата-центр — это комната с серверами.
Когда пользователь поисковой системы задает свой запрос,в 20-ти случаях из 100 получаются неоднозначные цели в вопросе. Например, если он пишет в строке поиска слово «Наполеон», то еще не известно, какой ответ ожидает — рецепт торта или биография великого полководца. Или фраза «Братья Гримм» — сказки, фильмы, музыкальная группа. Чтобы такой возможный веер целей сузить до конкретных ответов в Яндексе существует специальная технология Спектр. Она учитывает потребности пользователей, используя статистику поисковых запросов. Из всех вопросов, заданных в Яндексе посетителями, Спектр выделяет в них различные объекты (имена людей, названия книг, модели машин и т.д.) Эти объекты распределены по некоторым категориям. На сегодняшний момент таких категорий насчитывается более 60-ти. С помощью них поисковая система имеет в своей базе разные значения слов в запросах пользователей. Интересно, что эти категории периодически проверяются (анализ происходит пару раз в неделю), что позволяет Яндексу более точно давать ответы на поставленные вопросы.
На базе технологии Спектр Яндекс организовал диалоговые подсказки. Они появляются под поисковой строкой, в которой пользователь набирает свой неоднозначный запрос. В этой строке отражены категории, к которым может относится объект вопроса. От выбора пользователем такой категории зависят дальнейшие результаты поиска.
От 15 до 30% всех пользователей поисковой системы Яндекс желают получить только местную информацию (данные того региона, в котором они живут). Например, о новых фильмах в кинотеатрах своего города. Поэтому ответ на такой запрос должен быть разным для каждого региона. В связи с этим, Яндекс использует свою технологию поиска с учетом регионов. Например, вот такие ответы могут получить жители, которые ищут репертуар фильмов в своем кинотеатре «Октябрь»:
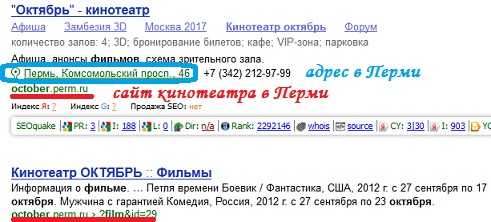
А вот такой результат получат жители города Ставрополь на тот же запрос:
Регион пользователя определяется в первую очередь по его ip-адресу. Иногда эти данные не точны, потому что ряд провайдеров могут сразу работать на несколько регионов, а значит и менять ip-адреса cвоим пользователям. В принципе, если такое случилось с Вами, Вы легко можете поменять в настройках в поисковой системе свой регион. Он указан в правом верхнем углу на странице выдачи результатов. Изменить его можно здесь.
Поисковая система Яндекс ру — результаты ответа
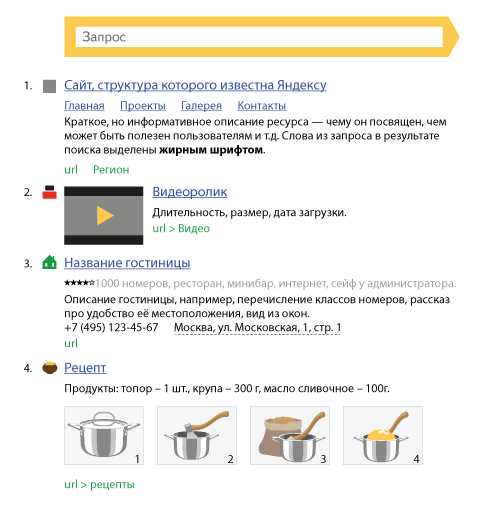
Когда Метапоиск подготовил ответ, поисковая система Яндекс должна выдать его на странице с результатами. Она представляет собой перечень ссылок на найденные документы с небольшой информацией по каждому. Задача технологии выдачи результатов — максимально информативно предоставить пользователю самые релевантные ответы. Шаблон одной такой ссылки выглядит следующим образом:
Рассмотрим эту форму результата поподробней. Для заголовка результата поиска Яндекс часто использует название заголовка страницы (то, что оптимизаторы прописывают в теге title). Если же его нет, то здесь появляются слова из названия статьи или поста. Если текст заголовка большой, поисковая система ставит в это поле его фрагмент, который больше всего релевантен к заданному запросу.
Очень редко, но бывает так, что заголовок не соответствует содержанию запроса. В таком случае Яндекс формирует свой заголовок результата поиска, используя текст в статье или посте. Он обязательно будет иметь слова запроса.
Для сниппета поисковая система использует весь текст на странице. Она выбирает все фрагменты, где присутствует ответ на запрос, а потом выбирает самый релевантный из них и вставляет в поле формы ссылки на документ. Благодаря такому подходу, грамотный оптимизатор может после увиденного сниппета его переделать, тем самым улучшив привлекательность ссылки.
Для лучшего восприятия результата на запрос пользователя, заголовки оформляются как ссылки в тексте (выделение синим цветом с подчеркиванием). Для привлекательности веб-ресурса и его узнаваемости добавляется фавикон — маленький фирменный значок сайта. Он появляется слева от текста в первой строке перед заголовком. Все слова, которые входили в запрос в ответе тоже выделены жирным шрифтом для удобства восприятия.
В последнее время в сниппет поисковая система Яндекса добавляет различную информацию, которая поможет пользователю еще быстрее и точнее найти свой ответ. К примеру, если пользователь в своем запросе пишет название какой-либо организации, то в сниппете Яндекс добавит адрес ее, контактные телефоны и ссылку на месторасположение в географических картах. Если поисковой системе знакома структура сайта, в котором есть документ с ответом для пользователя, он ее обязательно покажет. Плюс к этому Яндекс тут же может добавить в сниппет наиболее посещаемые страницы такого веб-ресурса, чтобы при желании посетитель смог сразу перейти в нужный ему раздел, экономя свое время.
Есть сниппеты, которые содержат в себе цену какого-либо товара для интернет-магазина, рейтинг отеля или ресторана в виде звездочек, другая интересная информация с различными цифрами о объектах в документах поиска. Задача такой информации — дать полный перечень данных о тех предметах или объектах, которые интересны пользователю.
В целом уже с различными примерами страница с ответами будет выглядеть так:
Ранжирование и асессоры
В задачу Яндекса входит не только поиск всех возможных вариантов ответа, но и подбор самых лучших (релевантных). Ведь пользователь не будет рыться во всех ссылках, которые ему предоставит в качестве результата поисков Яндекс. Процесс упорядочивания результатов поиска называется ранжированием. То есть именно ранжирование определяет качество предлагаемых ответов.
Есть правила, по которым Яндекс определяет релевантные страницы:
- понижение в позициях на странице с результатами ждут сайты, которые ухудшают качество поиска. Обычно это такие веб-ресурсы, владельцы которых пытаются обмануть поисковую систему. К примеру, это сайты со страницами, на которых находится бессмысленный или невидимый текст. Конечно, он видим и понятен поисковому роботу, но не посетителю, читающему этот документ. Или сайты, которые при переходе на ссылке в зоне выдачи сразу переводят пользователя совсем на другой сайт.
- не попадают в выдачу результатов или сильно понижаются в ранжировании сайты, содержащие в себе эротический контент. Это связано с тем, что часто такие веб-ресурсы используют агрессивные методы продвижения.
- зараженные вирусами сайты не понижаются в выдаче и не исключаются с результатов поиска — в этом случае пользователь информируется об опасности с помощью специального значка. Это связано с тем, что Яндекс предполагает, что на таких веб-ресурсах могут находиться важные документы по запросу посетителя поисковой системы.
К примеру, так будет ранжировать Яндекс сайты по запросу «яблоко»:
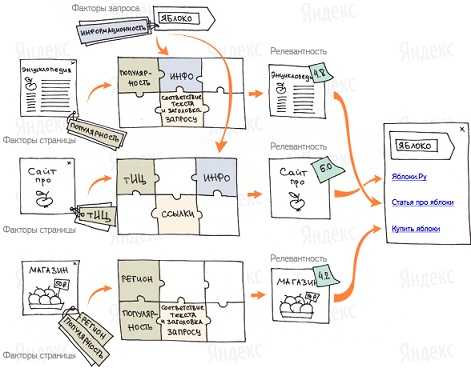
Кроме факторов ранжирования Яндекс использует специальные образцы с запросами и ответами на них, которые пользователи поисковой системы считают самыми подходящими. Такие образцы ни одна машина не сможет сделать на данный момент — это прерогатива человека. В Яндексе такие специалисты называются асессорами. В их задачу входит полный анализ всех документов поиска и оценка ответов на заданные запросы. Они выбирают лучшие ответы и составляют специальную обучающую выборку. В ней поисковая машина видит зависимость между релевантными страницами и их свойствами. Имея такую информацию Яндекс может подобрать для каждого запроса оптимальную формулу ранжирования. Метод построения такой формулы называется Матрикснет. Плюс этой системы в том, что она устойчива к переобучению, что позволяет учитывать большое количество факторов ранжирования, не увеличивая количество ненужных оценок и закономерностей.
Интересная статистика Яндекса
В завершении моего поста хочу показать вам интересную статистику, собранную поисковой системой Яндекса в процессе своей работы.
1. Популярность личных имён в России и российских городах (данные взяты из учетных записей блоггеров и пользователей социальных сетей в марте 2012 года).

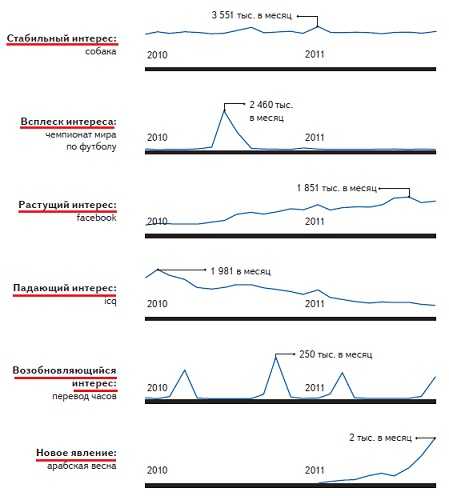
2. Статистика с различными типами интересов.
Мой пост о том, как работает поисковая система Яндекс завершен.
[stextbox id=»info» caption=»Великий провидец» mode=»css» direction=»ltr» shadow=»true» float=»true» width=»650″ bwidth=»2″ color=»000000″ ccolor=»ff0000″ bcolor=»000000″ bgcolor=»afeeee» cbgcolor=»eee8aa»]В 1863 году великий писатель Жюль Верн создал очередную свою книгу «Париж в ХХ веке». В ней он подробно описал метро, автомобиль, электрический стул, компьютер и даже сеть Интернет. Однако издатель отказался печатать книгу и она пролежала более 120 лет, пока ее не нашел правнук Жюля Верна в 1989 году. Издана была книга в 1994году.[/stextbox]
maksimdovzhenko.ru
Работа в Яндексе
Посмотрите ролик о том, как устроен процесс интервью в Яндексе.
1
Как на него попасть
Почти у каждой вакансии Яндекса есть тестовое задание — с него-то всё и начинается. Ответьте на вопросы на странице вакансии и отправляйте заявку. Если вы успешно справились с тестом и заинтересовали службу найма, то получите приглашение на встречу — обычно в течение недели.
Резюме
Подойдёт в любой форме, а для дизайнеров и разработчиков его заменит портфолио или ссылка на репозиторий. Хорошо сопроводить резюме вольным рассказом о том, почему вас стоит взять на работу. Будьте готовы вкратце пересказать ключевые факты на собеседовании — умение представить себя интересует не меньше биографии.
Сколько будет встреч
Чаще всего проводятся четыре собеседования. В некоторых случаях в зависимости от профессии кандидата решение о найме может быть принято по итогам двух встреч. На особо ответственные должности количество интервью может быть увеличено до пяти-шести.
2
Как оно проходит
Обычно встреча длится час или два. Вам предложат чай-кофе, воду и печеньки. Собеседование с претендентами на вакансию разработчика состоит из серии коротких встреч с разными экспертами. Рекрутер обязательно расскажет вам все подробности.Подробности для технических вакансий
Подробности для дизайнеров
Кто будет на собеседовании
Сотрудник отдела найма и ваш потенциальный руководитель. Если вы подходите на несколько ролей или претендуете на важную должность, к встрече могут присоединиться и другие эксперты.
Чего ожидать
Некоторые вопросы или задачки могут не касаться вакансии напрямую — так проверяется способность рассуждать в неизвестной ситуации. Также будьте готовы начертить схему маркером на стене или написать код на бумаге, без компьютера.
3
Что будет после
Между встречами и особенно после финального собеседования иногда наступает длинная пауза. Пожалуйста, наберитесь терпения. Если рекрутер не ответил на звонок или письмо — это не значит, что вы не справились. В это время служба найма может общаться с другими кандидатами, а итоговое тестовое задание часто проверяют много людей.
В случае успеха
Рекрутер сразу свяжется с вами и озвучит предложение Яндекса. В первый день в офисе вас встретят, помогут оформить документы в отделе кадров, получить оборудование и освоиться на рабочем месте.
Если отказали
Поищите другие вакансии — если вы не прошли тестовое задание или собеседование, ничто не мешает попробовать себя в другой роли. Или повторить заявку через какое-то время, когда наберётесь знаний и опыта.
yandex.by
Поиск Яндекса с инженерной точки зрения. Лекция в Яндексе / Яндекс corporate blog / Habr
Сегодня мы публикуем ещё один из докладов, прозвучавших на летней встрече об устройстве поиска Яндекса. Выступление руководителя отдела ранжирования Петра Попова получилось в тот день самым доступным для широкой аудитории: минимум формул, максимум общих понятий о поиске. Но интересно было всем, потому что Пётр несколько раз переходил к деталям и в итоге рассказал много такого, о чём Яндекс никогда раньше публично не заявлял.Кстати, одновременно с публикацией этой расшифровки начинается вторая встреча из серии, посвящённой технологиям Яндекса. Сегодняшнее мероприятие — уже не про поиск, а про инфраструктуру. Вот ссылка на трансляцию.
Ну а под катом — лекция Петра Попова и часть слайдов.
Меня зовут Пётр Попов, я работаю в Яндексе. Здесь я уже примерно семь лет. До этого программировал компьютерные игры, занимался 3D-графикой, знал про видеокарточки, писал на SSE-ассемблере, в общем, такими вещами занимался.
Надо сказать, что, устраиваясь на работу в Яндекс, я достаточно мало знал о предметной области — о том, что здесь люди делают. Знал только, что здесь работают хорошие люди. Поэтому испытывал некоторые сомнения.

Сейчас я расскажу достаточно полно, но не очень глубоко о том, как выглядит наш поиск. Что такое Яндекс? Это поисковик. Мы должны получить запрос пользователя и сформировать десятку результатов. Почему именно десятку? Пользователи чрезвычайно редко переходят на более далёкие страницы. Можно считать, что десять документов — это всё, что мы показываем.
Не знаю, есть ли в зале люди, которые занимаются рекламой Яндекса, потому что они считают, что основной продукт Яндекса — это совсем другое. Как обычно, здесь две точки зрения и обе правильные.
Мы считаем, что основное — это счастье пользователя. И, как ни удивительно, от состава десятки и того, как десятка отранжирована, это счастье зависит. Если мы ухудшаем выдачу, пользователи пользуются Яндексом меньше, уходят в другие поисковики, плохо себя чувствуют.

Какую конструкцию мы соорудили ради решения этой простой задачи — показать десять документов? Конструкция достаточно мощная, снизу, видимо, разработчики на неё взирают.
Наша модель работы. Нам нужно сделать всего несколько вещей. Нам нужно обойти интернет, проиндексировать получившиеся документы. Документом мы называем скачанную веб-страницу. Проиндексировать, сложить в поисковый индекс, запустить над этим индексом поисковую программу, ну и ответить пользователю. В общем-то, всё, профит.
Пройдемся по шагам этого конвейера. Что такое интернет и какого он объема? Интернет, считай, бесконечный. Возьмем любой сайт, который продает что-нибудь, какой-нибудь интернет-магазин, сменим там параметры сортировки — появится другая страничка. То есть можно задавать СGI-параметры страницы, и содержание будет совсем другое.
Сколько мы знаем принципиально значащих страниц с точностью до отбрасывания незначащих CGI-параметров? Сейчас — порядка нескольких триллионов. Скачиваем мы странички со скоростью порядка нескольких миллиардов страничек в день. И казалось бы, что нашу работу мы могли бы выполнить за конечное время, там, за два года.
Как мы вообще находим новые странички в интернете? Мы обошли какую-то страничку, вытянули оттуда ссылки. Они — наши потенциальные жертвы для скачивания. Возможно, за два года мы обойдем эти триллионы URL, но появятся новые, и в процессе парсинга документов появятся ссылки на новые странички. Уже тут видно, что наша основная задача — бороться с бесконечностью интернета, имея на руках конечные инженерные ресурсы в виде дата-центров.
Мы скачали все безумные триллионы документов, проиндексировали. Дальше нужно положить их в поисковый индекс. В индекс мы кладем не всё, а только лучшее из того, что скачали.
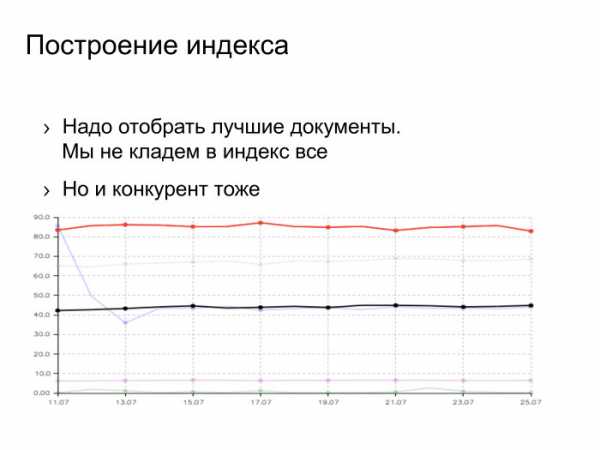
Есть товарищ Ашманов, широко известный в узких кругах специалист по поисковым системам в интернете. Он строит разные графики качества поисковых систем. Это график полноты поисковой базы. Как он строится? Задается запрос из редкого слова, смотрится, какие документы есть во всех поисковиках, это 100%. Каждый поисковик знает про какую-то долю. Сверху красным цветом мы, снизу черным цветом — наш основной конкурент.
Тут можно задаться вопросом: как мы такого достигли? Возможны несколько вариантов ответа. Вариант первый: мы пропарсили страничку с этими тестами, выдрали оттуда все URL, все запросы, которые задает товарищ Ашманов и проиндексировали странички. Нет, мы так не делали. Второй вариант: для нас Россия является основным рынком, а для конкурентов она — что-то маргинальное, где-то на периферии зрения. Этот ответ имеет право на жизнь, но он мне тоже не нравится.
Ответ, который мне нравится, заключается в том, что мы проделали большую инженерную работу, сделали проект, который называется «большая база», под это закупили много железа и сейчас наблюдаем этот результат. Конкурента тоже можно бить, он не железный.
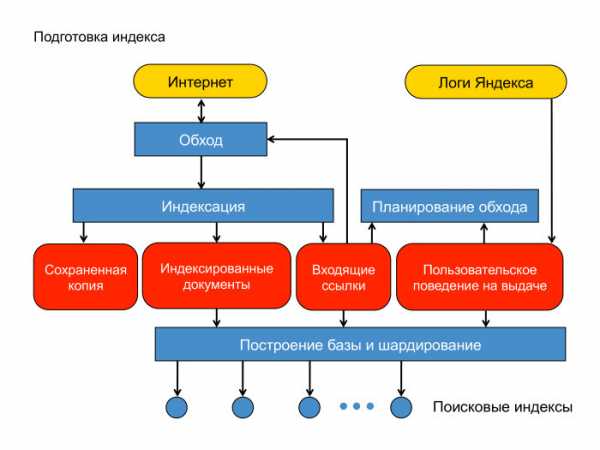
Документы мы скачали. Как мы строим поисковую базу? Вот схема нашей контент-системы. Есть интернет, облачко документов. Есть машины, которые его обходят — спайдеры, пауки. Документ мы скачали. Для начала — положили его в сохраненную копию. Это, фактически, отдельная междатацентровая хеш-таблица, куда можно читать и писать на случай, если мы потом захотим этот документ проиндексировать или показать пользователю как сохраненную копию на выдаче.
Дальше мы документ проиндексировали, определили язык и вытащили оттуда слова, приведенные согласно морфологии языка к основным формам. Ещё мы вытащили оттуда ссылки, ведущие на другие страницы.
Есть еще один источник данных, который мы широко используем при построении индекса и вообще в ранжировании — логи Яндекса. Задал пользователь запрос, получил десятку результатов и как-то там себя ведёт. Ему показались документы, он кликает или не кликает.
Разумно предположить, что если документ показался в выдаче, или, тем более, если пользователь по нему кликнул, провел какое-то взаимодействие, то такой документ нужно оставить в поисковой базе. Кроме того, логично предположить, что ссылки с такого хорошего документа ведут на документы, которые тоже хороши и которые неплохо бы приоритетно скачать. Здесь изображено планирование обхода. Стрелочка от планирования обхода должна вести в обход.
Дальше есть стадия построения поискового индекса. Эти округлые прямоугольнички лежат в MapReduce, нашей собственной реализации MapReduce, которая называется YT, Yandex Table. Тут я немножко лакирую — на самом деле построение базы и шардирование оперируют с индексами как с файлами. Мы это немножко зафиксим. Эти округлые прямоугольнички будут лежать в MapReduce. Суммарный объем данных здесь — порядка 50 ПБ. Тут они превращаются в поисковые индексы, в файлики.
В этой схеме есть проблемы. Основная связана с тем, что MapReduce — сугубо батчевая операция. Чтобы определить приоритетные документы для обхода, например, мы берем весь линковый граф, мёржим его со всем пользовательским поведением и формируем очередь для скачки. Это процесс достаточно латентный, занимающий какое-то время. Ровно так же с построением индекса. Там есть стадии обработки — они батчевые для всей базы. И выкладка так же устроена, мы или дельту выкладываем, или всё.
Важная задача при этих объемах — ускорить процедуру доставки индекса. Надо сказать, что эта задача для нас сложная. Речь идёт о борьбе с батчевым характером построения базы. У нас есть специальный быстрый контур, который качает всякие новости в real time, доносит до пользователя. Это наше направление работы, то, чем мы занимаемся.
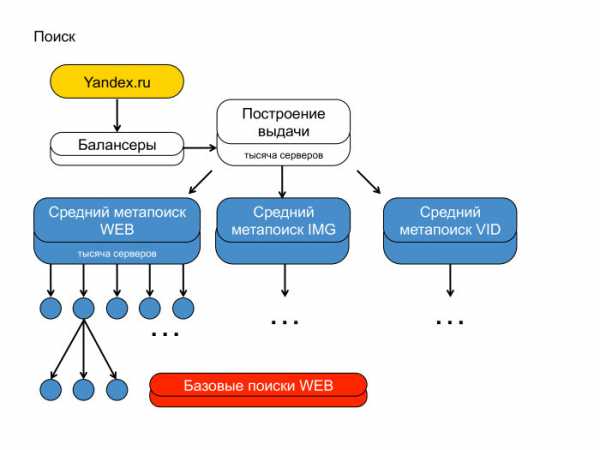
А вот вторая сторона медали. Первая — контент-система, вторая — поиск. Можно понять, почему я рисовал пирамидку — потому что поиск Яндекса действительно похож на пирамиду, такую иерархическую структуру. Сверху стоят балансеры, фронты, которые генерируют выдачу. Чуть пониже — агрегирующие метапоиски, которые агрегируют выдачу с разных вертикалей. Надо сказать, что на выдаче вы наверняка видели веб-документы, видео и картинки. У нас три разных индекса, они опрашиваются независимо.
Каждый ваш поисковый запрос уходит по этой иерархии вниз и спускается до каждого кусочка поисковой базы. Мы весь индекс, который построили, разбили на тысячи кусков. Условно, — на две-три-пять тысяч. Над каждым куском подняли поиск, и этот запрос всюду спустился.

Тут же видно, что поиск Яндекса — большая штука. Почему она большая? Потому что мы в своей памяти храним, как вы видели на предыдущих слайдах, достаточно репрезентативный и мощный кусок интернета. Храним не один раз: в каждом дата-центре от двух до четырёх копий индекса. Запрос наш спускается до каждого поиска, фактически проходится по каждому индексу. Сейчас используемые структуры данных — такие, что мы вынуждены всё это хранить напрямую в оперативке.

Что нужно делать? Вместо дорогой оперативки использовать дешевый SSD, ускорить поиск, допустим, в два раза, и получить профит — десятки или сотни миллионов долларов капитальных расходов. Но тут не нужно говорить: кризис, Яндекс экономит и всё такое. На самом деле всё, что мы сэкономим, мы пустим в полезное дело. Мы увеличим индекс в два раза. Мы будем по нему качественнее искать. И это то, ради чего осуществляется такого рода сложная инженерка. Это реальный проект, правда, достаточно тяжелый и вялотекущий, но мы действительно так делаем, хотим поиск наш улучшить.
Поисковый кластер не только достаточно большой — он ещё и очень сложный. Там реально крутятся миллионы инстансов разных программ. Я вначале написал — сотни тысяч, но товарищи из эксплуатации меня поправили — таки миллионы. На каждой машинке в очень многих экземплярах 10-20 штук точно крутится.
У нас тысячи разных типов сервисов размазаны по кластеру. Надо пояснить: кластер — это такие машинки, хосты, на них запущены программы, все они общаются по TCP/IP. Программы имеют разное потребление CPU, памяти, жесткого диска, сети — короче, всех этих ресурсов. Программы живут на хостах в общежитии. Точнее, если будем сажать одну программу на хост, то утилизация кластера будет никакой. Поэтому мы вынуждены селить программы друг с другом.
Дальше слайд про то, что с этим делать. А здесь — небольшое замечание, что все данные программы, все релизы мы катаем с помощью торрентов, и число раздач на нашем торрент-трекере превышает оное число на Pirate Bay. Мы реально большие.
Что нужно делать со всей этой кластерной конструкцией? Нужно улучшать механизмы виртуализации. Мы реально вкладываемся в разработку ядра Linux, у нас есть собственная система управления контейнерами а-ля Docker, про неё Олег подробнее расскажет.
Нам нужно заранее планировать, на каких хостах какие программы друг с другом селить, это тоже сложная задача. У нас постоянно что-то на кластер едет. Сейчас там наверняка десять релизов катятся.
Нам нужно грамотно селить программы друг с другом, нужно улучшать виртуализацию, нужно-таки объединить два больших кластера — роботный и поисковый. Мы как-то независимо заказывали железо и считали, что есть отдельно машинки с огромным числом дисков и отдельно — тонкие блейды для поиска. Сейчас мы поняли, что лучше заказывать унифицированное железо и запускать MapReduce и поисковые программы в изоляции: одно жрет в основном диски и сеть, второе в основном CPU, но по CPU у них баланс, нужно туда-сюда крутить. Это большие инженерные проекты, которые мы тоже ведем.
Что мы с этого получаем? Пользу в десятки миллионов долларов экономии капитальных расходов. Вы уже знаете, как мы эти деньги потратим — мы потратим их на улучшение нашего поиска.
Здесь я рассказал о конструкции в целом. Какие-то отдельные строительные блоки. Эти блоки люди долбили стамеской, и у них что-то получилось.

Ранжирующая функция Матрикснет. Достаточно простая функция. Можете почитать — там лежат в векторе бинарные признаки документа, а в этом цикле происходит вычисление релевантности. Я уверен, что среди вас есть специалисты, которые умеют на SSE программировать, и они бы живо это ускорили в десять раз. Так оно в какой-то момент и случилось. Тысяча строчек кода нам спасли 10-15% общего потребления CPU на нашем кластере, что опять же составляет десятки миллионов долларов капитальных расходов, которые мы знаем, как потратить. Это тысяча строчек кода, которая стоят очень дорого.
Мы более-менее вычистили из репозитория, соптимизировали, но там ещё есть что поделать.
Имеется у нас платформа для машинного обучения. Индексы с предыдущего слайда нужно подбирать жадным образом, перебирая все возможности. На CPU это делать долго. На GPU — быстро, зато пулы для обучения не лезут в память. Что нужно делать? Или покупать кастомные решения, куда этих железок много-много втыкается, или связывать машинки быстрым, использовать интерконнект какой-то, infiniband, учиться с этим жить. Оно типично глючит, не работает. Это очень забавный инженерный вызов, с которым мы тоже встречаемся. Он, казалось бы, совсем не связа с нашей основной деятельностью, но тем не менее.

Во что мы ещё инвестируем, так это в алгоритмы сжатия данных. Основная задача сжатия выглядит примерно следующим образом: есть последовательность целых чисел, нужно её как-то компрессировать, но не просто компрессировать — нужно ещё иметь случайный доступ к i-тому элементу. Типичный алгоритм — маленькими блоками сжать это, иметь разметку для общего потока данных. Такая задача — совсем другая, нежели контекстное сжатие типа zip или LZ-family. Там совсем другие алгоритмы. Можно сжать Хаффманом, Varlnt, блоками типа PFORX. У нас есть собственный патентованный алгоритм, мы его улучшаем, и это опять же 10-15% экономии оперативной памяти на простенький алгоритм.
У нас есть всякие забавные мелочи, например доработки в CPU, планировщики Linux. Там какая проблема с гипертредными камнями от Intel? То, что на физическом ядре есть два потока. Когда там два треда занимают два потока, то они работают медленно, латенция увеличивается. Нужно правильно раскидывать задачки по физическим процессорам.
Если раскидывать правильно, а не так, как делает стоковый планировщик, можно получить 10-15% латентности нашего запроса, условно. Это то, что видят пользователи. Сэкономленные миллисекунды умножайте на число поисков — вот и сэкономленное время для пользователей.
У нас есть какие-то совсем странные вещи типа собственной реализации malloc, который на самом деле не работает. Он работает в аренах, и каждая локация просто сдвигает указатель внутри этой арены. Ну и ref counter арены поднимает на единичку. Арена жива, пока жива последняя локация. Для всякой смешанной нагрузки, когда у нас есть короткоживущая и долгоживущая локация, это не работает, это выглядит как утечка памяти. Но наши серверные программы устроены не так. Приходит запрос, мы там аллоцируем внутренние структуры, как-то работаем, потом отдаем ответ пользователю, всё сносится. Этот аллокатор идеально работает для наших серверных программ, которые без состояния. За счет того, что все локации локальны, последовательны в арене, оно работает очень быстро. Там нет никаких page fault, cache miss и т. п. Очень быстро — это от 5% до 25% скорости работы наших типичных серверных программ.
Это инженерка, что ещё можно делать? Можно заниматься машинным обучением. Про это вам с любовью расскажет Саша Сафронов.
А сейчас вопросы и ответы.
Я возьму очень понравившийся мне вопрос, который пришел на рассылку и который следовало бы включить в мою презентацию. Товарищ Анатолий Драпков спрашивает: есть знаменитый слайд про то, как быстро росла формула до внедрения Матрикснета. На самом деле и до, и после. Есть ли сейчас проблемы роста?
Проблемы роста у нас стоят в полный рост. Очередной порядок увеличения числа итераций в формуле ранжирования. Сейчас мы там порядка 200 тысяч итераций делаем в функции Матрикснет, чтобы ответить пользователю. Был получен следующим инженерным шагом. Раньше мы ранжировали на базовых. Это значит, что каждый базовый запускает у себя Матрикснет и выдает сто результатов. Мы сказали: давайте мы лучшие сто результатов объединим на среднем и отранжируем ещё раз совсем тяжелой формулой. Да, мы это сделали, на среднем можно вычислять в нескольких потоках функцию Матрикснет, потому что ресурсов нужно в тысячу раз меньше. Это проект, который нам позволил достичь очередного порядка увеличения объемов ранжирующей функции. Что будет ещё — не знаю.
Андрей Стыскин, руководитель управления поисковых продуктов Яндекса:
— Сколько занимала байт первая формула ранжирования Яндекса?
Пётр:
— Десяток, наверное.
Андрей:
— Ну, да, наверное, где-то символов сто. А сколько сейчас занимает формула ранжирования Яндекса?
Пётр:
— Где-то 100 МБ.
Андрей:
— Формула релевантности. Это для наших смотрителей с трансляций, специалистов по SEO. Попробуйте зареверсинженирить наши 100 МБ ранжирования.
Алеся Болгова, Intel:
— По последнему слайду про malloc не могли бы пояснить, как вы выделяете память? Очень интересно.
Пётр:
— Берется обычная страничка, 4 КБ, в начале у нее rev counter, и дальше мы каждую аллокацию… если маленькие аллокации меньше страницы, мы просто двигаемся в этой страничке. В каждом треде, естественно, эта страничка своя. Когда страничку закрыли — всё, про неё забыли. Единственное, у неё rev counter в начале.
Алеся:
— То есть вы страницу выделяете?
Пётр:
— Внутри страницы аллокациями вот так растем. Единственное, страничка живет, пока в ней последняя аллокация живет. Для обычного workload это выглядит как утечка, для нашего — как нормальная работа.
— Как вы определяете качество страницы, стоит её класть в индекс или нет? Тоже машинное обучение?
Пётр:
— Да, конечно. У странички есть множество факторов, от её размера до показов на поиске, до…
Андрей:
— До robot rank. Она находится на каком-то хосте, в какой-то поддиректории хоста, на неё сколько-то входящих ссылок. Те, кто на неё ссылаются, обладают каким-то качеством. Все это берем и пытаемся предсказать, с какой вероятностью, если данную страничку скачать, на ней будет информация, которая попадет по какому-то запросу в выдачу. Это предсказывается, отбирается топ с учетом размера документов — потому что в зависимости от размера документа вероятность, что она хоть по какому-то запросу попадет, повышается. Задача об оптимальном наполнении рюкзака. Отбирается с учетом размера документа и кладется топовая в индекс.
— …
Андрей:
— Давай мы тебя представим сначала.
— Может, не стоит?
Андрей:
— Владимир Гулин, начальник ранжирования поисковика Mail.Ru.
Владимир:
— Первый мой вопрос — про количество поисков вообще. Вы говорили, что вы там драматически увеличили размер базы. Хочется вообще понимать, с какого объема вы стартовали, каков был объем русского индекса, иностранного индекса, сколько документов приходилось на каждый шард, ну и после увеличения…
Пётр:
— Это такие цифры, слишком технические. Может, в кулуарах я бы сказал. Я могу сказать, во сколько раз мы примерно увеличились — на полтора порядка где-то. В 30 раз, условно. За последние три года.
Владимир:
— Я тогда абсолютные цифры в кулуарах уточню.
Пётр:
— Да, за отдельную плату, что называется.
Владимир:
— Ладно. Что касается свежести — какой приблизительно сейчас в Яндексе объем быстрого индекса? И вообще с какой скоростью вы это всё обновляете, смешиваете?
Пётр:
— Индекс реально реалтаймовый, там порядка двух минут латенции на то, чтобы добавить документ в индекс. От момента, как мы его проиндексировали, и дискавери тоже — скачка быстрая.
Владимир:
— Но именно найти документ. Сначала надо узнать, что документ существует.
Пётр:
— Я понимаю, что вопрос такой — непонятно, когда в интернете появилась первая ссылка на данный документ. Когда мы узнали первую ссылку, то дальше это вопрос минут в быстром слое.
Андрей:
— Речь идет о миллионах документов, которые ежедневно находятся в этом быстром индексе. Про них обычно очень много внешней информации: упоминание в Твиттере, сайтмэпы, упоминание новости на сайте Lenta.ru. И так как мы перекачиваем чуть ли не каждую секунду морду Lenta.ru, мы очень быстро обнаруживаем эти документы и в течение единиц минут в худшем случае доставляем их до поиска. Они могут искаться. По сравнению с большим индексом речь идет про драматически маленькое число документов, это миллионы.
Пётр:
— Да, на 3-4 порядка меньше.
Андрей:
— Да, это миллионы документов, которые умеют обновляться real time.
Владимир:
— Миллионы документов в сутки?
Пётр:
— Побольше чуть-чуть, но примерно так, да.
Владимир:
— Теперь вопрос про смешивание свежих результатов и результатов основного поиска.
Пётр:
— У нас два способа смешивания. Один — документ той же формулой ранжируется, что и батчевый обычный документ. А второй — специальное новостное подмешивание, когда мы определяем интент запроса, понимаем, что он реально свежий и что нужно что-то такое показать. Два способа.
Владимир:
— Как вы боретесь с ситуацией, когда у вас по популярным запросам, где дофига кликов, появляются свежие результаты? Как вы определяете, что свежий результат надо показывать выше того результата, который уже накликан? Спросили у вас: «Google». Вы вроде знаете, какие результаты по такому запросу хорошие. Но тем не менее, в новостях ещё что-то, какие-то статьи…
Пётр:
— Это всякие запросные факторы, всякие тренды и всё такое.
Андрей:
— Для всех поясню, в чем сложность задачи и в чем вопрос. Про документ, который долго существует в интернете, мы много чего знаем. Мы много знаем входящих на него ссылок, знаем, сколько на нем люди проводили времени, а про свежие документы этого всего не знаем. Поэтому сложность задачи ранжирования свежих документов и новостей — угадывать, будут ли люди это читать, уметь предсказывать количество ссылок, которые он наберет за какое-то время, чтобы его показывать нормально. И для подмешивания документов по запросу «Google», когда Google что-то хорошее сделал, там существует некая оптимизационная метрика, которая у нас называется профицит. Мы её умеем оптимизировать.
Пётр:
— Мы знаем поток запросов, содержание свежескачанных страниц. Эти две вещи мы можем анализировать и понимать, что реально свежий запрос требует подмешивания.
Андрей:
— А потом, на основе ручной оценки и пользовательского поведения именно в эту секунду в этот день, мы понимаем, что именно сегодня эта новость по запросу важна и у неё есть такие факторы: документ только появился, на него столько-то ретвитов. И поэтому следующую новость, которая будет с таким же распределением признаков, тоже нужно показывать, когда она наберет соответствующие значения.
Пётр:
—А факторы там могут быть такими: число найденного в обычном слое против числа найденного по этому запросу в свежем. Такие, самые наивные, хотя мы его выпиливаем тщательно.
Андрей:
— Для тех, кого пугает слово «факторы», специально будет третий доклад, где мы расскажем базовые принципы — как вообще устроено машинное обучение, ранжирование, что такое факторы, как с помощью этого сделать поисковик, который выдает нормальные хорошие результаты.
Владимир:
— Спасибо, остальное спрошу потом.
Никита Пустовойтов:
— Получается, у вас существует большое количество урлов, про которые вы в принципе знаете, а качать вы можете на несколько порядков меньше. Поскольку за время скачивания будут появляться новые, больше вы никогда не посетите. Для выбора применяется машинное обучение, какие-то эвристики?
Пётр:
—Только машинное обучение. Идея там простая: мы имеем сигнал на какой-то документ, любой, число показов, и его распространяем по ссылочному графу. Всё это агрегируем на странице «цель ссылки», дальше машинным обучением так же обучаем шанс показаться, исходя из этих данных.
Никита:
— Второй вопрос — инженерный. Вы говорили, что у вас много CPU-затратных задач. Рассматривали ли вы вариант использования процессора Xeon Phi от Intel? Он вроде гораздо быстрее работает с оперативной памятью, чем GPU.
Пётр:
— Мы его рассматривали для задач обучения именно нашего Матрикснета, нашей формулы, и там он феерично плохо себя показал. А так вообще у нас профиль очень плоский, у нас топовая функция где-то 1,5%. Мы всё, что можно, руками соптимизировали, а так у нас портянки С++-кода, который туда не ложится.
— Насколько я знаю, Яндекс был первым поисковиком, который начал работать с русской морфологией. Скажите, на данный момент это всё ещё является каким-либо преимуществом или все поисковики одинаково хорошо работают с русской морфологией?
Пётр:
— Сейчас в области морфологии наука не стоит на месте. Саша Сафронов расскажет о том, чего мы сейчас достигаем, там реально есть новые подходы и новые способы решения проблем. Например, определение запросов, похожих на этот, по пользовательскому поведению. Не расширение отдельных слов, а расширение запросов запросами.
Андрей:
— То есть это не совсем морфология. Морфологию действительно, наверное, все поисковики более-менее освоили, но это базовая вещь. А вот лингвистика, нахождение, чем и какие слова запроса можно расширить, какие ещё вещи стоит поискать в документе, чтобы найти кандидатов, которые будут более релевантные — про это будет третий доклад. Там наше ноу-хау, мы расскажем.
Пётр:
— По крайней мере, намекнем.
Андрей (зритель):
— Спасибо за краткий экскурс в столь сложную технологию, как поиск Яндекса. Использует ли Яндекс deep learning и алгоритмы обучения с подкреплением в построении быстрого индекса или кеша? Вообще если используете где-то, то как?
Пётр:
— Deep learning используем для того, чтобы факторы ранжирования обучать. Безотносительно к быстрому или медленному индексу. Он используется для картинок, веба и всего такого.
Андрей Стыскин:
— Летом запустили версию ранжирования, которая дала 0,5% прироста качества, где мы правильно сварили deep learning на словах. Приезжали наши бывшие коллеги из-за границы и рассказывали, что там такое не работает, а мы научились.
Пётр:
— А может, это потому, что мы для топ-100 документов это делаем. Речь идёт об очень затратной задаче. Наш способ построения пайплайна поиска позволяет для сотни документов это делать.
Андрей Стыскин:
— Невозможно посчитать deep learning для всех кандидатов, которых сотни миллионов на запросы, но для топа документов можно провернуть, и у нас эта схема поиска ровно так работает — позволяет такие очень сложные наукоемкие алгоритмы внедрять.
Игорь:
— Про будущее поисковика в целом. Интернет сейчас растет очень быстро, объем, наверное, растет экспоненциально. Уверены ли вы, что через 10 лет вы будете успевать за ростом интернета, и уверены ли, что будете охватывать его в таком же объеме? Повторите ещё раз, в каком объеме сейчас интернет охвачен по вашей оценке, и что будет через 10 лет?
Пётр:
— К сожалению, можно только процентно по отношению с кем-то степень охвата определять. Потому что он реально бесконечный.
Андрей:
— Это красивый философский вопрос. Пока мы в нашем коллективе за законом Мура успеваем, каждый год кратно увеличиваем наш размер базы. Но это правда сложно, правда интересно, и, конечно же, нам даже не хватает рук, чтобы это делать, но мы хотим и знаем, как это увеличивать в ближайшие несколько лет некоторыми сериями улучшений.
Пётр:
— 10 лет — слишком далеко, но ближайшие годы да, осилим.
Андрей (зритель):
— Сколько весит реплика интернета, как она разносится между ДЦ, и как осуществляется синхронизация реплик?
Пётр:
— Полный объем роботных данных — порядка 50 ПБ, реплика меньше, индекс меньше. Можете умножить на коэффициент, который вам кажется разумным. Вы же инженер, прикиньте.
Андрей:
— А как разносится?
Пётр:
— Разносится банально — через torrent, torrent share. Потом качаем этот файлик.
Андрей:
— То есть в какой-то момент времени они не консистентны?
Пётр:
— Нет, там потом консистентные переключения. Бывает, что переключаем по ДЦ, когда ночью оно вдруг не консистентно.
Андрей:
— То есть можно через F5 — если нажимаем, один документ имеем…
Пётр:
— Мы боремся с этой проблемой, знаем о ней, ее решение стоит в наших планах.
Иван:
— Как вы боретесь с различными бот-системами и за что можно отправиться в бан?
Пётр:
— У нас есть специальные люди, которые знают ответ на этот вопрос, но они не скажут.
Андрей Стыскин:
— На сегодняшнем мероприятии мы хотели поговорить про технические детали.
Пётр:
— Про роботоловилку мы можем ответить. Нас действительно регулярно ддосят, поэтому у нас прямо на балансере, на первом слое, когда запрос попадает, есть детекция, что запрос из какой-то сети пришел негодной. Это быстро обновляется, мы быстро реджектим, оно не валит наш кластер.
Андрей:
— И это тоже устроено методом машинного обучения. Показывается капча, и в зависимости от того, как ты её разгадываешь, мы получаем положительные и отрицательные примеры. На каких-то факторах — типа айпишника подсетки, какого-то поведения, времени между действиями — обучаем и баним или не баним такие запросы. DDoS не пройдет.
Андрей Аксёнов, Sphinx Search:
— У меня технические вопросы. Проходной вопрос — почему память? Неужели даже децл подисковать на SSD не получается, чтобы индекс чуть-чуть не влезал, изредка упирался в SSD?
Пётр
— Там получается так, что футпринт одного запроса порядка 50-100 МБ, он прямо жесткий. С такой скоростью ты не сможешь сервить тысячу запросов в секунду, как мы хотим. Мы работаем над тем, чтобы этот футпринт уменьшить. Проблема, что данные про документ рассыпаны по всему диску. Мы хотим их собрать в одно место, и тогда наша общая мечта осуществится.
Андрей Аксёнов:
— Упирается в bandwidth или latency?
Пётр:
— В оба. Мы и последовательно пейджфолдимся, и объемы большие.
Андрей Аксёнов:
— То есть невероятно, но факт: даже если чуть-чуть…
Пётр:
— Да, даже если чуть-чуть отожрешь — всё.
Андрей Аксёнов:
— Экспоненциальное падение во много раз?
Пётр:
— Да-да.
Андрей Аксёнов:
— Теперь важнейший вопрос для промышленного хозяйства: сколько классов строка и классов векторов в базе?
Пётр:
— А вот всё меньше и меньше.
Андрей Аксёнов:
— Ну конкретнее.
Пётр:
— У нас пришли правильные люди, они насаждают правильные порядки. Сейчас это число уменьшается.
Андрей Аксёнов:
— Векторов-то сколько и строк?
Пётр:
— Сейчас векторов, наверное, даже один-два максимум.
Андрей Аксёнов:
— Один не бывает, два хоть…
Пётр:
— Ну вот видишь.
Андрей Аксёнов:
— А строк?
Пётр:
— Ну должен же быть корпоративный какой-то дух Яндекса.
Андрей Аксёнов:
— Скажи, не томи, ну.
Пётр:
— Строк две минимум. Ну три, может.
Андрей Аксёнов:
— Не пять?
Пётр:
— Не пять.
Андрей Аксёнов:
— Налицо прогресс, спасибо.
Фёдор:
— Про вашу схему с метапоисками. У вас очень высокий каскад. Какие тайминги на каждом уровне, можете озвучить?
Пётр Попов:
— Прямо сейчас вставляем ещё один слой, не хватает. Времена ответов… Средний метапоиск делает три раунда хождений туда-сюда, у него порядка 250 мс, 95-я квантиль. Дальше построение выдачи не очень быстрое, но вся конструкция где-то за 700 мс отрабатывает.
Андрей Стыскин:
— Да, там выше JavaScript, так что это 250 мс, а там 700.
Пётр:
— То, что снизу, оно делает кучу раундов. У нас тоже специалисты заняты прямо сейчас решением этой проблемы.
Фёдор:
— У вас нарисовано три группы вертикалей. Но у вас есть ещё Афиша, Новости и так далее. Где вы их замешиваете в итоге?
Пётр:
— В построении выдачи у нас есть такой блендер, который объединяет все эти вертикали, по пользовательскому поведению решает, кого показать. Это как раз построение выдачи.
Андрей:
— Вертикалей порядка сотни, это слой, который называется верхним метапоиском. В нём сливаются результаты средних метапоисков из вертикали веба, Картинок, Видео и ряда других, а также из маленьких базовых источников типа Афиши, Расписаний, ТВ и Электричек.
Пётр:
— Это к вопросу о том, почему у нас тысячи разных типов программ. Там очень много всяких источников, оно набегает.
Фёдор:
— Раз у вас так много вертикалей, есть ли среди них сторонние, которые не вы считаете?
Пётр:
— Особо нет. Реклама наша тоже вертикальная, отдельно от поиска, но стороннего особо нет.
Артём:
— У вашего основного конкурента выдача всегда была real time, он дельта-индексами докидывал. А у Яндекс был up выдачи. Складывалось впечатление, что темной ночью раз в семь дней человек нажимает рычаг и раскатывает индексы.
Пётр:
— К сожалению, так и происходит.
Артём:
— Правильно понимаю, что быстрый индекс был сделан для того, чтобы актуализировать выдачу real time?
Пётр:
— Да, но решение общее. Многие так реально делают, в том числе и наш основной конкурент.
Артём:
— Стремитесь ли вы к тому, чтобы тоже дельта-индексами подкидывать, просто отказаться от быстрого индекса?
Пётр:
— Естественно, стремимся. Ещё бы знать, как.
Артём:
— Когда это можно ожидать?
Пётр:
— Хороший вопрос. На тех же графиках Ашманова видно, как мы обновляем индекс. Сейчас это видно меньше, и мы делаем так, чтобы это проходило совсем быстро и незаметно. Такова одна из наших задач.
Артём:
— Вы каждый раз обрабатываете запрос пользователя? Приходит запрос, вы отсылаете его на бэкенд, рассчитывается формула и результат?
Пётр:
— Есть кеши, но они работают в 50% случаев. 40-50% запросов пользователей — уникальные и никогда больше не будут заданы. Очень много по-настоящему уникальных запросов пользователей вообще за всю жизнь Яндекса. Кешируем 50-60%. Для кеширования тоже своя система.
habr.com